Чому новий процесор швидше на такій же частоті?

Ми незалежно перевіряємо товари та технології, які рекомендуємо.

Якщо ви готові самостійно вибирати процесор, рекомендуємо скористатися профільним розділом каталогу. Тут можна відсортувати підходящі моделі за різними параметрами, у тому числі тактовими частотами, поколінням (кодовим назвам), об'ємом кеш-пам'яті тощо.
Чому частота процесорів майже не зростає?
Наприкінці 90-х років 20 століття зі швидкістю зростання тактових частот процесорів міг конкурувати хіба що темп інфляції. Від десятків МГц процесори швидко перейшли до сотень, а потім і до ГГц. Це зростання давало збільшення кількості виконуваних за секунду операцій, тобто прямо підвищувало швидкодію. Але вже в середині «нульових» років ця гонка зупинилася. Умовний Pentium 4 тих років мав близько 3 ГГц, а сьогодні у багатьох Core i5 співставні частоти.
Понад 10 років активного приросту немає. Чому так? Насамперед через тепловиділення (TDP). Щоб далі піднімати частоту чипів, треба збільшувати робочу напругу. Воно прямо впливає на кількість тепла, що виділяється процесором – його численними транзисторами.
Так, щоб двократно збільшити тактову частоту, доведеться підняти тепловиділення приблизно у 8 разів. У такому сценарії точно не обійтися без крутої системи охолодження, ймовірно, водяної. Через те, що зростання «герцовок» уперлося у показники TDP інженерам довелося змінювати підходи до роботи.

Ще підвищувати частоти можна з допомогою вдосконалення техпроцесів. Логіка тут така: чим меншими будуть складові чипа, тим швидше пройдуть сигнали і вище виявиться швидкість роботи. Перехід на тонкіші техпроцеси відбувається в режимі нон-стоп: в 2024 вже дісталися до 4 нм, а 10 років тому 22 нм були одкровенням.
Щоправда, практично відчутного приросту частот тонший техпроцес не дає. Просто поки нанометри (нм) зменшуються, фізичні розміри кристалів зростають, збільшується кількість ядер, а отже сигнали долають майже такі самі відстані, що й раніше.
Виходить так, що до нового технологічного прориву в процесоробудуванні не варто очікувати на активне зростання частот. Отже приріст швидкодії відбуватиметься з допомогою інших методів оптимізації.

















Що сьогодні робить процесори швидшими?
Сьогодні збільшувати продуктивність та швидкодію чипів допомагає оптимізація процесорної мікроархітектури, яка націлена на:
- обчислювальні ядра;
- підсистеми пам'яті (різні види кешу та проміжні буфери обміну);
- шини передачі даних.
Основна робота інженерів Intel та AMD найчастіше спрямована на збільшення показника Instruction Per Clock (IPC) — кількості виконуваних інструкцій за такт. Якщо вдається підняти IPC, процесор робить більше обчислень і працює швидше, ніж його попередники. З нуля чипи робляться вкрай рідко: зазвичай нове покоління – це результат усунення наявних «вузьких місць», доопрацювання існуючих блоків, програмної оптимізації тощо.
Непрямим методом підвищення ефективності чипів виступає зниження тепловиділення на кожну обчислювальну операцію. Але це не так фактор швидкодії, як спосіб підвищити стабільність тактових частот при високих або граничних навантаженнях.
Зупинимося на основних методах прискорення сучасних процесорів докладніше.
Оптимізація обчислювальних ядер
Сучасні чипи дотримуються конвеєрної обробки, тобто розбивають інструкції, що поступають на виконання, на велику кількість простих операцій. Це нагадує типовий конвеєр на заводі, де кожен виконавець робить лише щось одне. Процеси йдуть не послідовно, а паралельно, що підвищує загальну продуктивність.
Щоправда, якісні зміни ведуть до ускладнення процесорів. Так, за кожну операцію в інструкції відповідає свій блок. Плюс у нових поколіннях чипів з'являються додаткові елементи, які покликані прискорити конвеєр, підняти його пропускну здатність, знизити простої (ще сильніше дроблячи інструкції, що надходять, на дрібні операції) тощо.
Ось лише деякі блоки та приклади їх модернізації:
- Branch Predictors – модулі передбачення переходів. Вони прогнозують наперед виконання тих чи інших інструкцій від запущених програм. Поліпшення тут скорочує кількість хибних прогнозів, через що загальна продуктивність підвищується.
- Decoders – декодери. Перетворюють складні команди від програм у найпростіші мікрооперації. У нові ядра додають більше декодерів, завдяки чому процесор за одиницю часу готовий виконувати більше інструкцій (за умови модернізації і інших блоків).
- Schedulers – планувальники виконання. Це блоки, що вибудовують чергу з інструкцій. Апгрейд планувальника забезпечує обчислювальні ядра роботою без простоїв.
- Register File – регістровий файл. Елемент, який зберігає коди команди, доки вона виконується. Модернізація може стосуватися розширення сховища, що, зі свого боку, збільшить пропускну здатність за операціями, що виконуються.
- Execution Ports – виконавчі порти. Це ті самі блоки, які реалізують окремі етапи інструкцій. Приклад покращення – збільшення числа таких портів. У результаті одночасно у роботі виявляється більше операцій, підвищується швидкість виконання інструкцій.
- Load/Store – блок збереження/завантаження. Він відповідає за збереження та завантаження даних із пам'яті. Удосконалення цього блоку підвищує ефективність взаємодії процесора із пам'яттю.
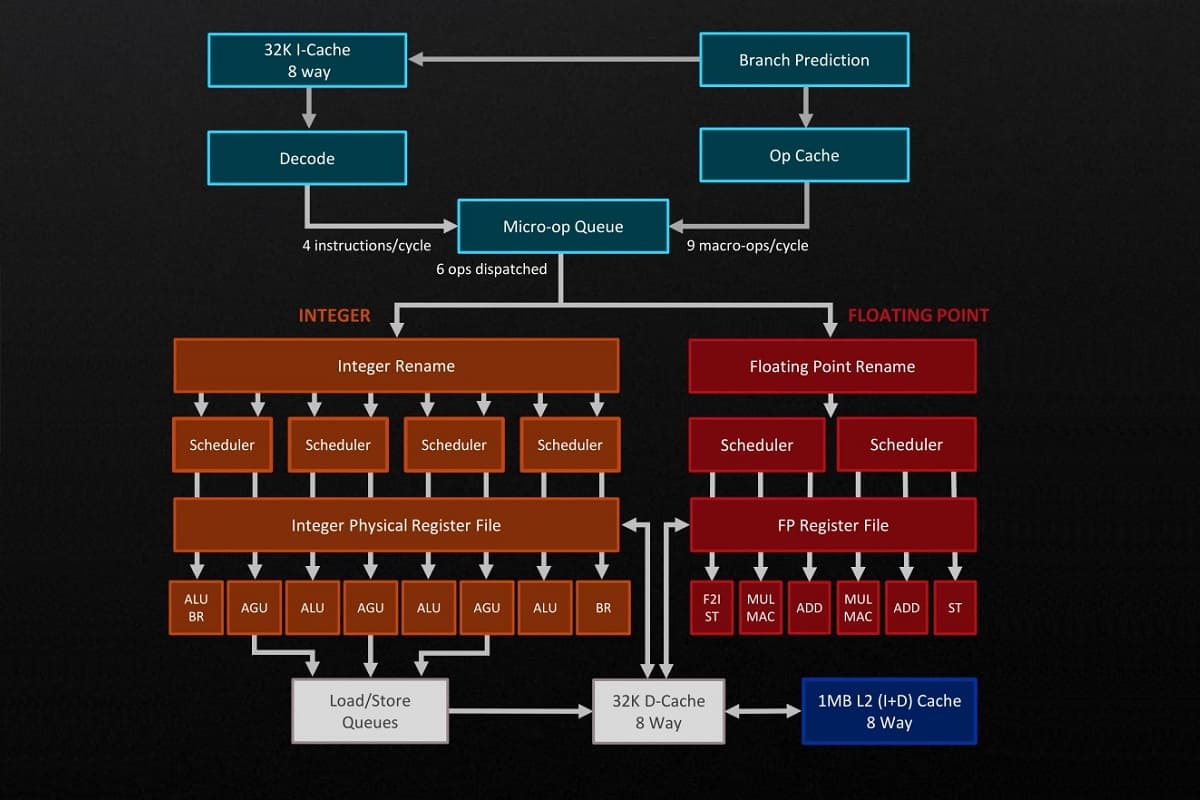
Структура обчислювальних ядер складна, а блоків стає дедалі більше. Але це означає, що можливості для подальшого підвищення швидкодії точно не вичерпані.
Поліпшення підсистеми пам'яті
На кількість виконуваних процесором інструкцій за такт впливає не тільки ефективність обчислювальних блоків, а й робота підсистеми пам'яті. У сучасних чипах обов'язково є кілька видів кешу та проміжні буфери. Кожен із рівнів від L0 до L3 покликаний прискорювати роботу в рамках своєї зони відповідальності – певного обчислювального етапу.

Багаторівнева організація кешу в процесорах використовується невипадково. Зі збільшенням об'єма пам'ять незмінно стає повільніше. Тому кеш першого рівня обчислюється кілобайтами, але гарантує максимальну швидкодію. Одночасно і приріст об'єму кешу L3 (у нових процесорах вони часом перевищують 100 МБ) теж обґрунтований, адже збільшує кількість даних, які можна зберігати та мати швидкий доступ до них.
Отже, найочевидніші методи прискорення процесора за рахунок підсистеми пам'яті — збільшувати кількість та пропускну здатність кешу. Але цим модернізація не обмежується, а також може включати:
- Зміни в організації кешу. Сьогодні все частіше використовують так званий неінклюзивний варіант. Дані не дублюються на всіх рівнях кешу, а відстежуються та підбираються з урахуванням прогнозів. В результаті на L0 знаходиться найнеобхідніше зараз, а на L3 – витісняється непотрібне для економії місця.
- Оптимізація кількості каналів. Доступ до даних у кеші найчастіше здійснюється за різними «ланцюжками». Чим більше каналів, тим вище можливість знайти необхідне в підсистемі пам'яті. Але багатоканальність може й ускладнити доступ до кешу, що негативно вплине на продуктивність. Відповідно, потрібно шукати оптимальний баланс.
- Збільшення додаткових (проміжних) буферів.
А ще для зростання обчислювального потенціалу та швидкодії комп'ютера загалом нові процесори оснащують покращеними контролерами — сумісними з останніми поколіннями ОЗП, у тому числі DDR5 з високими частотами.









Прискорення шин передачі даних
У багатоядерних процесорах на загальну швидкодію впливає швидкість передачі даних між обчислювальними ядрами та іншими компонентами чипа. Відповідно, не останнє значення має і шина, що застосовується.
У кожного виробника використовуються свої фірмові розробки:
- у Intel – кільцева шина Ring Bus;
- у AMD – сполучна шина Infinity Fabric.
Як правило, поліпшення шин відбуваються один раз на кілька поколінь. Цього достатньо, щоб покрити потреби у швидкодії, зумовлені зростанням кількості та обчислювального потенціалу ядер.
Що прискорює процесори Intel?
Архітектурні покращення та їх вплив на швидкодію наочно простежується на актуальних прикладах. У Intel великих стрибків тактових частот немає, але показники Instruction Per Clock все одно зростають. Так, не в кожному поколінні, але тенденція очевидна.

У 2021 році компанія представила чипи під кодовою назвою Rocket Lake. Ці десктопні процесори 11-го покоління стали швидшими за попередників Comet Lake на 10-12%. А все завдяки таким архітектурним апгрейдам:
- розширений блок Decoders: стало можливим виконання 5 інструкцій, замість 4;
- збільшено кількість виконавчих портів до 10 (раніше було 8);
- модернізований блок Load/Store;
- зросли об'єми проміжних буферів, кешу L2 та L1;
- прискорено кеш першого рівня.
Через рік вийшли процесори Alder Lake та Raptor Lake — відповідно 12-те та 13-те покоління. З огляду на попередника зростання швидкодії цих моделей становило 15-20%. Тут відбулися такі зміни архітектури:
- знову покращений декодер – здатний виконувати 6 інструкцій за такт;
- збільшено кількість Execution Ports до 12;
- додано підтримку ОЗП DDR5;
- збільшено та прискорено кеші всіх рівнів, а також проміжні буфери.
Змін у Raptor Lake у порівнянні з Alder Lake мало. Так, у 13-му поколінні чипів збільшилася кількість енергоефективних ядер Gracemont і побільшало кешу L2 та L1. Показники IPC залишилися приблизно на тому самому рівні.
Покоління Raptor Lake Refresh дебютувало восени 2023 року і фактично стало косметичною доробкою чипів Raptor Lake. Архітектурних змін тут немає, лише зросла кількість енергоефективних ядер та впроваджено деякі програмні вдосконалення, включаючи політику диспетчеризації. Апгрейд вилився у збільшення тактових частот на 100-200 МГц. Так, тут є прямий приріст швидкодії. Він дещо вибивається на фоні актуальних тенденцій: його можна вважати винятком, яке підтверджує правило.
Основні відмінності в мікроархітектурі актуальних процесорів Intel (без 14-го покоління) зведені в таблицю:
| Кодова назва | Rocket Lake | Alder Lake | Raptor Lake |
|---|---|---|---|
| Покоління | 11 | 12 | 13 |
| Техпроцес | 14 нм | 10 нм | 10 нм |
| Кількість інструкцій у роботі | 5 | 6 | 6 |
| Число виконавчих портів | 10 | 12 | 12 |
| Збільшення кешу L1 | + (на 150%) |
+ | - |
| Збільшення кешу L2 | + (на 250%) |
+ | + (до 2 МБ на ядро) |
| Збільшення кешу L3 | - | + | + (до 4 МБ на кластер) |
| Прискорення кешу | + (для L1) |
+ (для рівнів) |
- |
| Інші нововведення | апгрейд блока Load/Store, збільшені інші буфери | підтримка ОЗП DDR5, збільшені інші буфери | більше енергоефективних ядер Gracemont, підтримка DDR5-5600 |
| Приріст швидкодії на тлі попередників з тією самою частотою, % | 10-12 | 15-20 | - |




Що прискорює процесори AMD?
Безпосередній вплив оптимізації процесорної мікроархітектури на швидкість роботи добре помітна і в процесорах AMD. Простежимо зміни, починаючи з чипів Zen3.
Процесори AMD із кодовим позначенням Cezanne вийшли наприкінці 2020 року. Це п'яте покоління, яке на тлі Zen2 стало на 20% швидше і наздогнало за продуктивністю на один потік Intel (відстаючи до цього багато років). А все завдяки таким покращенням:
- удосконалено блок Branch Predictors;
- кількість виконавчих портів збільшено до 8;
- оптимізовано блоки Schedulers — їх поменшало, але швидкодія подвоїлася;
- покращено блок Load/Store;
- збільшено об'єм кешу третього рівня та проміжних буферів.
У середині 2022 року вийшло 6-е покоління процесорів AMD – Zen4 Raphael. Тут відбувся перехід на 5 нм техпроцес, плюс були впроваджені різні нововведення на рівні мікроархітектури, завдяки чому IPC зріс на 13%. Що ж стало краще:
- новий апгрейд модуля передбачення переходів;
- контролери з підтримкою ОЗП DDR5;
- удвічі збільшено кеш L2 – до 1 МБ на ядро замість 0.5 МБ;
- модернізований блок Load/Store;
- збільшено регістровий файл та проміжні буфери.
На початку 2024 року були представлені гібридні десктопні процесори Zen4 Phoenix. Особливість цього покоління – поява компактних обчислювальних ядер Zen 4c. Вони стали меншими, але зберегли продуктивність (IPC) попередників Raphael, що говорить і про підвищення енергоефективності. Компактні ядра можуть комбінуватися зі звичайними, що в перспективі додасть варіативності виробникам.
Зазначимо, що влітку 2024 року дебютує нове покоління процесорів AMD – Granite Ridge (Zen5). На момент написання матеріалу вони ще не надійшли у продаж, але для них заявлений приріст швидкодії (Instruction Per Clock) на 16%.
Основні відмінності у мікроархітектурах актуальних процесорів AMD (без Zen5) представлені у таблиці:
| Кодова назва | Zen3 Cezanne | AMD Zen4 Raphael | Zen4 Phoenix |
|---|---|---|---|
| Покоління | 6 | 7 | 8 |
| Техпроцес | 7 нм | 5 нм | 4 нм |
| Поліпшення модулів передбачення переходів | + | + | немає даних |
| Число виконавчих портів | 8 | 8 | 8 |
| Збільшення кешу L1 | - | - | - |
| Збільшення кешу L2 | - | + (до 1 МБ на ядро) |
- |
| Збільшення кешу L3 | + (до 16 МБ на 8 ядер) |
- | - |
| Прискорення кешу | - | - | - |
| Інші нововведення | апгрейд блока Load/Store, збільшено інші буфери, використовується монолітний кеш L3 | підтримка ОЗП DDR5, збільшено регістровий файл та інші буфери, апгрейд блока Load/Store | скорочення габаритів обчислювальних ядер – поява Zen 4c |
| Приріст швидкодії на тлі попередників з тією самою частотою, % | 20 | 13 | - |
Висновки та рекомендації
При виборі процесора більшість покупців за звичкою дивляться лише на тактові частоти і кількість ядер, ігноруючи інші параметри. У поточних реаліях основний приріст швидкодії у деталях — в оптимізації процесорної мікроархітектури. Тому за можливістю перед покупкою варто звертати увагу на нововведення в блоках обчислювальних ядер, зміни об'єма кешу різних рівнів і навіть оновлення шин передачі даних.
Основний приріст IPC – кількості виконуваних інструкцій за такт – зазвичай дають явні вдосконалення мікроархітектури. Хоча практично багато залежить від вирішуваних задач і конкретних програм. Один софт працює швидше за рахунок модернізації обчислювальних блоків, а інший – за рахунок збільшення та прискорення підсистеми пам'яті.







Статті, огляди, корисні поради
Усі матеріали




