Dlaczego nowy procesor jest szybszy przy tej samej częstotliwości?

Niezależnie testujemy rekomendowane przez nas produkty i technologie.

Jeśli jesteś gotowy, aby samodzielnie wybrać procesor, zalecamy skorzystanie z rozdziału profilowego w katalogu. Tutaj możesz sortować odpowiednie modele według różnych parametrów, w tym prędkości zegara, generacji (nazw kodowych), rozmiaru pamięci podręcznej itp.
Dlaczego częstotliwość procesorów prawie nie wzrasta?
Pod koniec lat 90. XX wieku tempu wzrostu częstotliwości taktowania procesorów mogło dorównać jedynie tempo inflacji. Od kilkudziesięciu MHz procesory szybko przeszły do setek, a następnie do GHz. Wzrost ten przełożył się na wzrost liczby operacji wykonywanych na sekundę, czyli bezpośrednio zwiększył wydajność. Ale już w połowie 2000 roku wyścig ten utknął w martwym punkcie. Konwencjonalny Pentium 4 z tamtych lat miał około 3 GHz, a dziś wiele Core i5 ma porównywalne częstotliwości.
Od ponad 10 lat nie obserwuje się aktywnego wzrostu. Dlaczego? Przede wszystkim ze względu na rozpraszanie ciepła (TDP). Aby jeszcze bardziej zwiększyć częstotliwość chipów, konieczne jest zwiększenie napięcia roboczego. Ma to bezpośredni wpływ na ilość ciepła generowanego przez procesor - jego liczne tranzystory.
Aby więc podwoić częstotliwość zegara, trzeba będzie zwiększyć rozpraszanie ciepła około 8 razy. W takim scenariuszu zdecydowanie nie można obejść się bez układu chłodzenia, prawdopodobnie wodnego. W związku z tym, że rozwój procesorów Hertz natrafił na wskaźniki TDP, inżynierowie musieli zmienić swoje podejście do pracy.

Częstotliwości można również zwiększyć poprzez ulepszenie procesów technicznych. Logika jest następująca: im mniejsze elementy chipa, tym szybciej będą przesyłane sygnały i tym większa będzie prędkość robocza. Przejście na cieńsze procesy techniczne następuje non-stop: w 2024 roku osiągnęliśmy już 4 nm, a 10 lat temu rewelacją było 22 nm.
To prawda, że w praktyce bardziej subtelny proces technologiczny nie zapewnia zauważalnego wzrostu częstotliwości. Tyle, że podczas gdy nanometry (nm) maleją, fizyczne wymiary kryształów rosną, wzrasta liczba rdzeni, co oznacza, że sygnały pokonują niemal takie same odległości jak poprzednio.
Okazuje się, że do czasu nowego przełomu technologicznego w konstrukcji procesorów nie należy spodziewać się aktywnego wzrostu częstotliwości. Oznacza to, że wzrost wydajności nastąpi dzięki innym metodom optymalizacji.

















Co sprawia, że dzisiejsze procesory są szybsze?
Dziś zwiększać wydajność i prędkoś czipów pomaga optymalizacja mikroarchitektury procesorów, która jest skupiona na:
- rdzeniach obliczeniowych;
- podsystemach pamięci (różne typy pamięci podręcznej i schowków pośrednich);
- magistralnych danych.
Główna praca inżynierów Intela i AMD często ma na celu zwiększenie wskaźnika Instruction Per Clock (IPC) - liczby instrukcji wykonywanych na takt. Jeśli uda się podnieść IPC, wówczas procesor wykona więcej obliczeń i będzie działał szybciej niż jego poprzedniki. Chipy niezwykle rzadko powstają od zera: zwykle nowa generacja jest wynikiem wyeliminowania istniejących wąskich gardeł, udoskonalenia istniejących bloków, optymalizacji oprogramowania itp.
Pośrednią metodą zwiększenia wydajności chipów jest zmniejszenie rozpraszania ciepła dla każdej operacji obliczeniowej. Ale to nie tyle czynnik wydajności, co sposób na zwiększenie stabilności częstotliwości przy wysokich lub ekstremalnych obciążeniach.
Przyjrzyjmy się bliżej głównym sposobom przyspieszenia nowoczesnych procesorów.
Optymalizacja rdzeni obliczeniowych
Nowoczesne chipy przylegają do przetwarzania potokowego, czyli rozbijają przychodzące instrukcje do wykonania na wiele prostszych operacji. Przypomina to typową linię montażową w fabryce, gdzie każdy pracownik robi tylko jedną rzecz. Procesy nie przebiegają sekwencyjnie, ale równolegle, co zwiększa ogólną produktywność.
To prawda, że zmiany jakościowe prowadzą do bardziej złożonych procesorów. Zatem każda operacja w instrukcji ma swój własny blok. Dodatkowo w nowych generacjach chipów pojawiają się dodatkowe elementy, które mają za zadanie przyspieszyć proces, zwiększyć przepustowość układu, skrócić przestoje(jeszcze bardziej dzieląc przychodzące instrukcje na małe operacje) itp.
Oto tylko niektóre bloki i przykłady ich modernizacji:
- Branch Predictors - predyktory branżowe. Przewidują z wyprzedzeniem wykonanie określonych instrukcji z uruchomionych programów. Udoskonalenia w tym zakresie zmniejszają liczbę błędnych prognoz, co poprawia ogólną wydajność.
- Decoders - dekodery. Przekształcają złożone polecenia z programów w najprostsze mikrooperacje. Do nowych rdzeni dodawane są kolejne dekodery, dzięki czemu procesor jest gotowy na wykonanie większej liczby Instruction Per Clock (pod warunkiem modernizacji pozostałych bloków).
- Schedulers - harmonogramy wykonania. Są to bloki kolejkujące instrukcje. Aktualizacja harmonogramu gwarantuje, że rdzenie obliczeniowe będą działać bez przestojów.
- Register File - rejestrowy plik. Element przechowujący kody poleceń podczas ich wykonywania. Modernizacja może dotyczyć rozbudowy pamięci masowej, co z kolei wpłynie na zwiększenie przepustowości realizowanych operacji.
- Execution Ports - porty wykonawcze. Są to te same bloki, które realizują poszczególne etapy instrukcji. Przykładem poprawy jest zwiększenie liczby takich portów. Dzięki temu jednocześnie wykonywanych jest więcej operacji, a szybkość wykonywania instrukcji wzrasta.
- Load/Store - zapisanie/ładowanie bloku. Odpowiada za zapisywanie i ładowanie danych z pamięci. Ulepszenie tego bloku zwiększa efektywność interakcji pomiędzy procesorem a pamięcią.
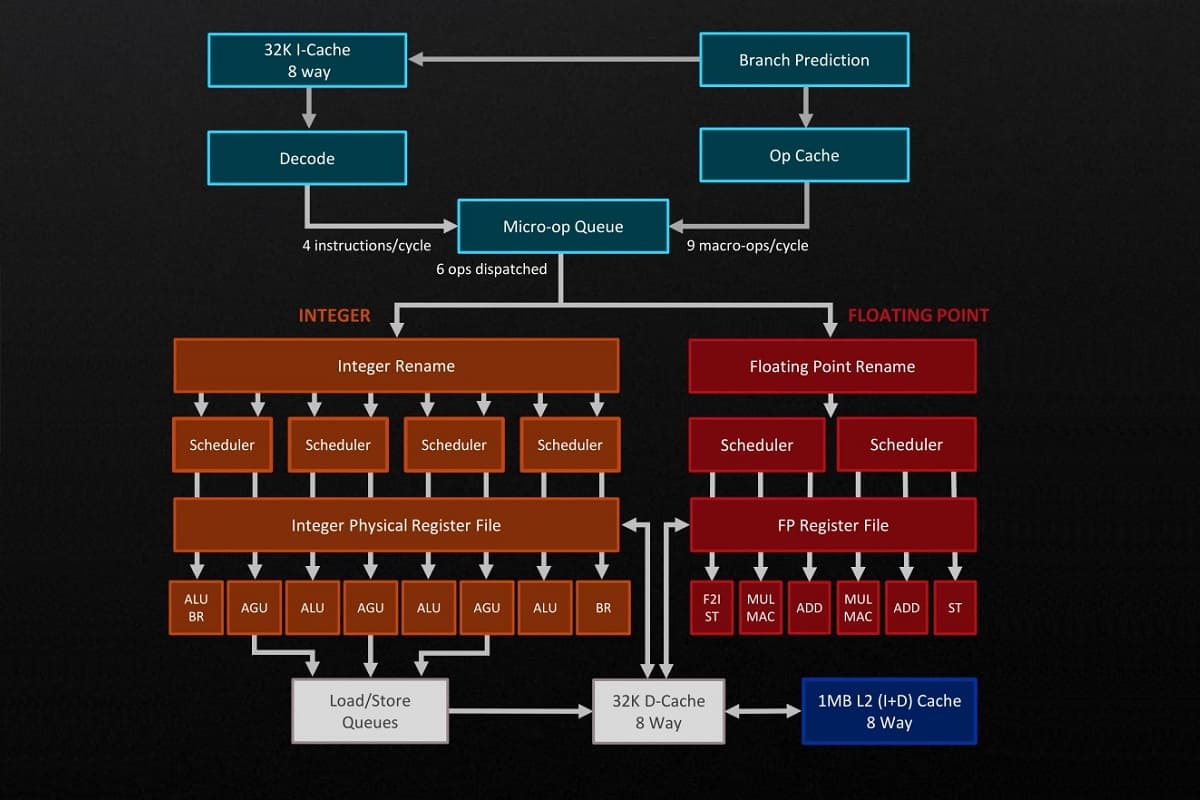
Struktura rdzeni obliczeniowych jest złożona, a liczba bloków rośnie. Oznacza to jednak, że możliwości dalszego zwiększania wydajności z pewnością nie zostały wyczerpane.
Ulepszony podsystem pamięci
Na liczbę instrukcji wykonywanych przez procesor w jednym cyklu zegara wpływa nie tylko wydajność jednostek obliczeniowych, ale także praca podsystemu pamięci. Nowoczesne chipy koniecznie mają kilka rodzajów pamięci podręcznej i buforów pośrednich. Każdy z poziomów od L0 do L3 ma na celu przyspieszenie pracy w ramach swojego obszaru odpowiedzialności – określonego etapu obliczeniowego.

Wielopoziomowa organizacja pamięci podręcznej w procesorach nie jest stosowana przypadkowo. Wraz ze wzrostem rozmiaru pamięci, niezmiennie staje się ona wolniejsza. Dlatego pamięć podręczna pierwszego poziomu jest obliczana w kilobajtach, ale gwarantuje maksymalną wydajność. Jednocześnie zwiększenie objętości pamięci podręcznej L3 (w nowych procesorach czasami przekracza ona 100 MB) jest również uzasadnione, ponieważ zwiększa liczba danych, które można przechowywać i szybko uzyskać do nich dostęp.
Zatem najbardziej oczywistymi metodami przyspieszania procesora za pomocą podsystemu pamięci jest zwiększenie liczby i przepustowości pamięci podręcznej. Ale modernizacja nie ogranicza się do tego i może również obejmować:
- Zmiany w organizacji pamięci podręcznej. Obecnie coraz częściej stosowana jest tzw. opcja nieinkluzywna. Dane nie są duplikowane na wszystkich poziomach pamięci podręcznej, ale są śledzone i wybierane na podstawie przewidywań. Dzięki temu L0 zawiera najpotrzebniejsze w danym momencie rzeczy, a L3 wypiera to, co niepotrzebne, aby zaoszczędzić miejsce.
- Optymalizacja liczby kanałów. Dostęp do danych w pamięci podręcznej często odbywa się za pośrednictwem różnych „łańcuchów”. Im więcej kanałów, tym większe prawdopodobieństwo znalezienia tego, czego potrzebujesz w podsystemie pamięci. Jednak wielokanałowość może również komplikować dostęp do pamięci podręcznej, co negatywnie wpłynie na wydajność. W związku z tym należy szukać optymalnej równowagi.
- Zwiększenie dodatkowych (pośrednich) buforów.
Aby zwiększyć potencjał obliczeniowy i szybkość komputera jako całości, nowe procesory wyposaża się w ulepszone kontrolery - kompatybilne z najnowszymi generacjami pamięci RAM, w tym DDR5 o wysokich częstotliwościach.









Przyspieszenie magistrali danych
W procesorach wielordzeniowych na ogólną wydajność wpływa prędkość przesyłania danych między rdzeniami przetwarzającymi a innymi elementami chipa. W związku z tym zastosowana magistrala nie jest najmniej istotna.
Każdy producent korzysta z własnych, zastrzeżonych rozwiązań:
- Intel ma magistralę pierścieniową ;
- AMD ma magistralę połączeniową Infinity Fabric.
Z reguły ulepszenia magistrali odbywają się raz na kilka pokoleń. To wystarczy, aby pokryć potrzeby wydajnościowe spowodowane wzrostem liczby i potencjału obliczeniowego rdzeni.
Co „przyspiesza” procesory Intela?
Udoskonalenia architektoniczne i ich wpływ na wydajność są wyraźnie zademonstrowane na rzeczywistych przykładach. Intel nie notuje dużych skoków taktowania, ale wskaźniki Instruction Per Clock wciąż rosną. Tak, nie w każdym pokoleniu, ale tendencja jest oczywista.

W 2021 roku firma wprowadziła na rynek chipy o nazwie kodowej Rocket Lake. Te procesory do komputerów stacjonarnych 11. generacji są o 10–12% szybsze niż ich poprzednicy Comet Lake. A wszystko dzięki tym udoskonaleniom architektonicznym:
- Rozszerzono siedzisko Decoders: możliwe stało się wykonanie 5 instrukcji zamiast 4;
- liczba portów wykonawczych została zwiększona do 10 (poprzednio było ich 8);
- zmodernizowano siedzisko Load/Store;
- Wzrosła objętość buforów pośrednich oraz pamięci podręcznych L2 i L1;
- Pamięć podręczna pierwszego poziomu została przyspieszona.
Rok później wypuszczono procesory Alder Lake i Raptor Lake - odpowiednio 12. i 13. generacji. W porównaniu do poprzednika wzrost wydajności tych modeli wyniósł 15–20%. Zaszły tu następujące zmiany architektoniczne:
- Dekoder został ponownie ulepszony - jest w stanie wykonać 6 Instructions Per Clock;
- liczba portów wykonawczych została zwiększona do 12;
- dodano obsługę pamięci RAM DDR5;
- powiększono i przyspieszono pamięci podręczne wszystkich poziomów, a także bufory pośrednie.
Raptor Lake ma kilka zmian w porównaniu do Alder Lake. Tym samym w 13. generacji chipów wzrosła liczba energooszczędnych rdzeni Gracemont i pojawiło się więcej pamięci podręcznej L2 i L1. Wskaźniki IPC pozostały prawie na tym samym poziomie.
Generacja Raptor Lake Refresh zadebiutowała jesienią 2023 roku i była właściwie kosmetyczną aktualizacją chipów Raptor Lake. Nie ma tu żadnych zmian architektonicznych, jedynie zwiększono liczbę energooszczędnych rdzeni i wprowadzono pewne usprawnienia oprogramowania, m.in. politykę wysyłkową. Modernizacja spowodowała podwyższenie częstotliwości taktowania o 100 – 200 MHz. Następuje więc bezpośredni wzrost wydajności. Odbiega nieco od obecnych trendów: można go uznać za wyjątek potwierdzający regułę.
Główne różnice w mikroarchitekturze obecnych procesorów Intel (bez 14. generacji) podsumowano w tabeli:
| Nazwa | Rocket Lake | Alder Lake | Raptor Lake |
|---|---|---|---|
| Pokolenie | 11 | 12 | 13 |
| Proces techniczny | 14 nm | 10 nm | 10 nm |
| Liczba instrukcji w pracy | 5 | 6 | 6 |
| Liczba portów wykonawczych | 10 | 12 | 12 |
| Zwiększ pamięć podręczną L1 | + (o 150%) |
+ | - |
| Zwiększenie pamięci podręcznej L2 | + (o 250%) |
+ | + (do 2 MB na rdzeń) |
| Zwiększenie pamięci podręcznej L3 | - | + | + (do 4 MB na klaster) |
| Zwiększenie pamięci podręcznej | + (dla L1) |
+ (dla poziomów) |
- |
| Inne innowacje | Aktualizacja bloku ładowania/zapisu, zwiększenie innych buforów | Obsługa pamięci RAM DDR5, zwiększono inne bufory | bardziej energooszczędne rdzenie Gracemont, obsługa DDR5-5600 |
| Wzrost wydajności w porównaniu do poprzedników o tej samej częstotliwości, w% | 10 – 12 | 15 – 20 | - |




Co „przyspiesza” procesory AMD?
Bezpośredni wpływ optymalizacji mikroarchitektury procesora na szybkość działania jest wyraźnie widoczny w procesorach AMD. Prześledźmy zmiany, zaczynając od układów Zen3.
Procesory AMD o nazwie kodowej Cezanne zostały wypuszczone pod koniec 2020 roku. To piąta generacja, która w porównaniu do Zen2 stała się o 20% szybsza i dogoniła Intela pod względem wydajności na wątek (wcześniej pozostając w tyle przez wiele lat). A wszystko dzięki tym ulepszeniom:
- poprawiono Branch Predictors;
- liczba portów wykonawczych została zwiększona do 8;
- bloki harmonogramów zostały zoptymalizowane – jest ich mniej, ale wydajność została podwojona;
- zmodernizowano blok Load/Store;
- zwiększono objętość pamięci podręcznej trzeciego poziomu i buforów pośrednich.
W połowie 2022 roku wypuszczono na rynek 6. generację procesorów AMD – Zen4 Raphael. Nastąpiło przejście na technologię procesową 5 nm, a także wprowadzono różne innowacje na poziomie mikroarchitektury, dzięki czemu IPC wzrósł o 13%. Co lepsze:
- nowa aktualizacja predyktora przejścia;
- kontrolery obsługujące pamięć RAM DDR5;
- podwojono pamięć podręczną L2 - do 1 MB na rdzeń zamiast 0,5 MB;
- zmodernizowano blok Load/Store;
- powiększono plik rejestru i bufory pośrednie.
Z początkiem 2024 roku wprowadzono hybrydowe procesory do komputerów stacjonarnych Zen4 Phoenix. Najważniejszym wydarzeniem tej generacji jest pojawienie się kompaktowych rdzeni obliczeniowych Zen 4c. Stały się one mniejsze, ale zachowały produktywność (IPC) swoich poprzedników Raphael, co również wskazuje na zwiększoną efektywność energetyczną. Rdzenie kompaktowe można łączyć ze zwykłymi, co w przyszłości zwiększy różnorodność producentów.
Latem 2024 roku zadebiutuje nowa generacja procesorów AMD – Granite Ridge (Zen5). W chwili pisania tego tekstu nie weszła jeszcze do sprzedaży, ale twierdzi się, że zapewni wzrost wydajności (zgodnie z Instruction Per Clock) o 16%.
Główne różnice w mikroarchitekturach obecnych procesorów AMD (bez Zen5) przedstawiono w tabeli:
| Nazwa | Zen3 Cezanne’a | AMD Zen4 Raphael | Zen4 Feniks |
|---|---|---|---|
| Pokolenie | 6 | 7 | 8 |
| Proces techniczny | 7 nm | 5 nm | 4 nm |
| Udoskonalanie predyktorów przejścia | + | + | brak danych |
| Liczba portów wykonawczych | 8 | 8 | 8 |
| Zwiększenie pamięci podręcznej L1 | - | - | - |
| Zwiększenie pamięci podręcznej L2 | - | + (do 1 MB na rdzeń) |
- |
| Zwiększenie pamięci podręcznej L3 | + (do 16 MB dla 8 rdzeni) |
- | - |
| Zwiększenie pamięci podręcznej | - | - | - |
| Inne innowacje | Aktualizacja bloku Load/Store, zwiększenie innych buforów, użycie monolitycznej pamięci podręcznej L3 | Obsługa pamięci RAM DDR5, większy plik rejestru i różne bufory, aktualizacja bloku Load/Store | zmniejszenie rozmiaru rdzeni obliczeniowych – pojawienie się Zen 4c |
| Wzrost wydajności w porównaniu do poprzedników o tej samej częstotliwości, w% | 20 | 13 | - |
Wnioski i Rekomendacje
Wybierając procesor, większość kupujących z przyzwyczajenia patrzy tylko na częstotliwości i liczbę rdzeni, ignorując inne parametry. W obecnych realiach główny wzrost wydajności leży w szczegółach - w optymalizacji mikroarchitektury procesora. Dlatego jeśli to możliwe, przed zakupem należy zwrócić uwagę na innowacje w blokach rdzeni obliczeniowych, zmiany wielkości pamięci podręcznej na różnych poziomach, a nawet aktualizacje magistrali przesyłania danych.
Główny wzrost IPC – liczby Instruction Per Clock – zwykle wynika z oczywistych ulepszeń w mikroarchitekturze. Chociaż w praktyce wiele zależy od rozwiązywanych zadań i konkretnych programów. Jedno oprogramowanie działa szybciej poprzez modernizację jednostek obliczeniowych, a drugie poprzez zwiększenie i przyspieszenie podsystemu pamięci.







Artykuły, recenzje, przydatne porady
Wszystkie materiały




